

Photo credit: DeepRoute.ai
Summary: On September 8, DeepRoute.ai unveiled its assisted driving platform, DeepRoute IO 2.0, and a new Vision-Language-Action (VLA) model at IAA Mobility 2025 in Munich. The company has secured over 10 vehicle programs and delivered over 100,000 vehicles equipped with its urban NOA system. To support its global strategy, DeepRoute.ai is expanding into Europe, Japan, and South Korea, focusing on both domestic and international collaboration. The versatile IO 2.0 architecture adapts to various vehicle types and configurations. The VLA model enhances decision-making with strong reasoning capabilities and improved interpretability, facilitating better understanding across diverse driving environments.
Beijing (Gasgoo)- On Sept. 8, Chinese autonomous driving company DeepRoute.ai debuted its latest generation assisted driving platform, DeepRoute IO 2.0, along with its self-developed Vision-Language-Action (VLA) model at IAA Mobility 2025 in Munich, Germany.
Up to now, the company has secured more than 10 designated vehicle model programs and delivered over 100,000 mass-produced vehicles equipped with its urban NOA (Navigation on Autopilot) system. DeepRoute.ai also plans to advance Robotaxi services built on mass-production platforms.
As part of its globalization strategy, DeepRoute.ai is actively expanding into Europe, Japan, and South Korea. The company is pursuing a dual-track approach: supporting domestic customers such as smart in their overseas ventures, while also working closely with international and joint-venture automakers to provide highly localized, adaptive assisted driving solutions.
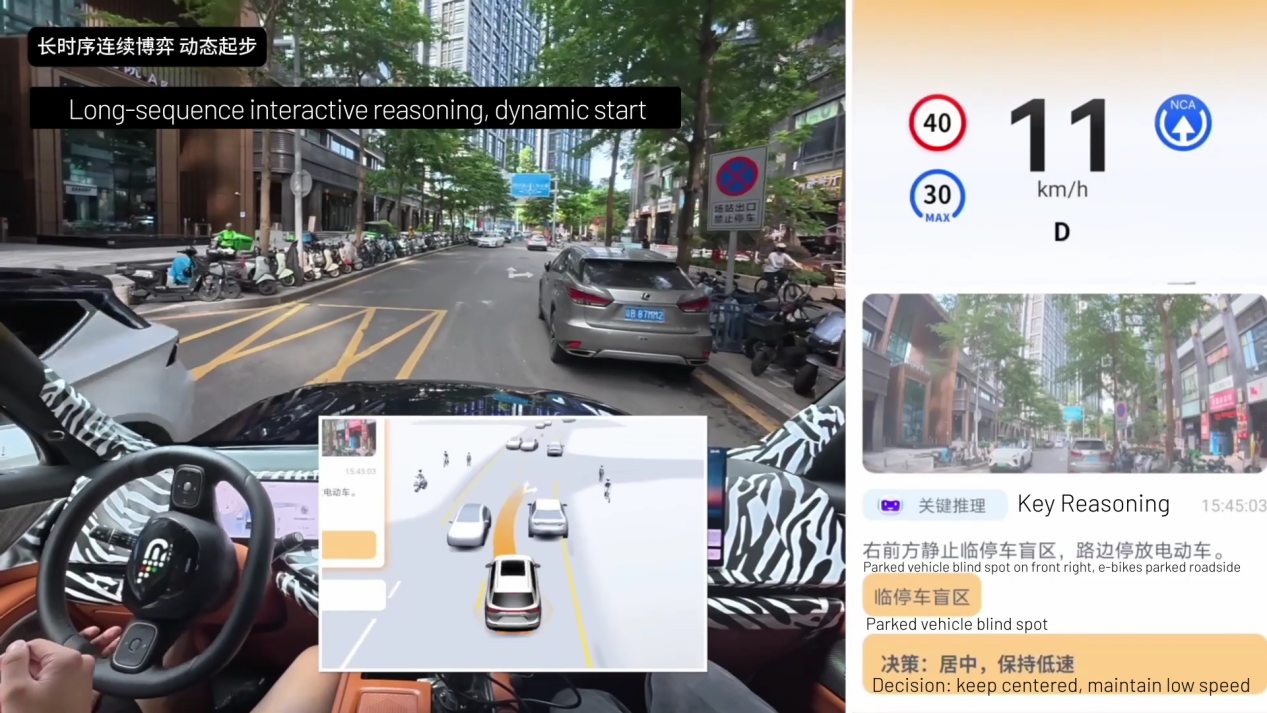
Photo credit: DeepRoute.ai
DeepRoute IO 2.0 features high flexibility with a “multi-modal, multi-chip, multi-vehicle” architecture. It supports both LiDAR-based and vision-only configurations, and can be adapted to SUVs, MPVs, sedans, and off-road vehicles to meet varied customer deployment needs.
At its core, the VLA model leverages chain-of-thought reasoning to deliver stronger temporal logic and better comprehension of complex road scenarios. Compared with traditional end-to-end models, VLA offers high interpretability and traceable decision paths, addressing the “black box” challenge in autonomous driving. Enhanced by large language model integration, VLA incorporates extensive knowledge bases, enabling robust semantic understanding and generalization across different road systems, languages, and driving cultures.


GIPHY App Key not set. Please check settings