
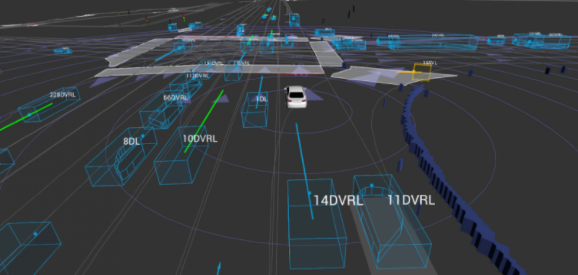
Following the release of the Perception Dataset and the conclusion of its 2019 object detection competition, Lyft today shared a new corpus — the Prediction Dataset — containing the logs of movements of cars, pedestrians, and other obstacles encountered by its fleet of 23 autonomous vehicles in Palo Alto. Coinciding with this, the company plans to launch a challenge that will task entrants with predicting the motion of traffic agents.
A longstanding research problem within the self-driving domain is creating models robust and reliable enough to predict traffic motion. Lyft’s data set focuses on motion prediction by including the movement of traffic types its fleet crossed paths with, like cars, cyclists, and pedestrians. This movement is derived from data collected by the sensor suite mounted to the roof of Lyft’s vehicles, which captures things like lidar and radar readings as the vehicles drive tens of thousands of miles:
- Logs of over 1,000 hours of traffic agent movement
- 170,000 scenes lasting about 25 seconds each
- 16,000 miles of data from public roads
- 15,000 semantic map annotations
- The underlying HD semantic map of the area
When paired with the semantic high-definition maps built by Lyft’s teams across Palo Alto, London, and Munich, the corpus contains the pieces needed to create prediction models enabling vehicles to choose safe trajectories in given scenarios, according to Lyft’s Sacha Arnoud and Peter Ondruska. “Data is the fuel for experimenting with the latest machine learning techniques, and limited access to large-scale, quality self-driving data shouldn’t hinder experimentation on this research problem,” they wrote in a blog post. “With this data set and competition, we aim to empower the research community, accelerate innovation, and share insight on which problems to solve from the perspective of a mature [autonomous vehicle] program.”
The training data set and accompanying Python-based software kit is available starting today. Testing and validation sets will be released as part of the competition, which will begin in August on Google’s Kaggle platform and will award $30,000 in total prizes.
“We believe self-driving will be a crucial part of a more accessible, safer, and sustainable transportation system,” continued Arnoud and Ondruska. “By sharing data with the research community, we hope to illuminate important and unsolved challenges in self-driving. Together, we can make the benefits of self-driving a reality sooner.”
The kickoff of Lyft’s second challenge comes months after Waymo expanded its public driving data set and launched the $110,000 Waymo Open Dataset competition. Winners were announced mid-June during a workshop at the 2020 Conference on Computer Vision and Pattern Recognition (CVPR), which was held online this year due to the coronavirus pandemic.
Source: venturebeat.com


GIPHY App Key not set. Please check settings